
Mise à jour le 21 décembre 2007
- Installation : déposez le fichier memo.php à la racine de votre site. (Remarque : le bouton mémo ne fonctionne qu’à partir de SPIP 1.7.
- Configuration : il faut préciser dans quelle rubrique doivent tomber les articles créés, quel statut est nécessaire pour pouvoir utiliser le bouton mémo, etc. Puis mettre « oui » dans la case « activer ».
- Utilisation : glissez le lien dans la barre des signets (bookmarks) de votre navigateur. Vous allez ensuite sur n’importe quelle page du web : si vous cliquez alors sur le signet, une fenêtre s’ouvre vous demandant de préciser le titre de la page. Si vous validez, la page est « photocopiée » dans ce site.
Si vous complétez le titre en ajoutant, entre parenthèses, le nom de la source, ce dernier ira directement dans le champ « nom_site » de la page photocopiée [1]...
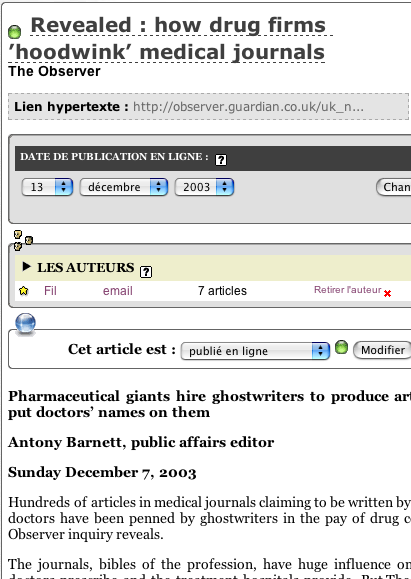
En images, cela donne :
1. - Nous sommes sur la page à photocopier
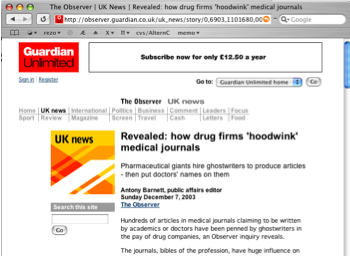
2. - Clic !
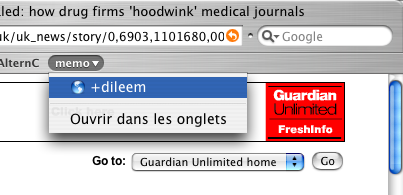
3. - Une boîte de dialogue s’affiche avec le titre de la fenêtre
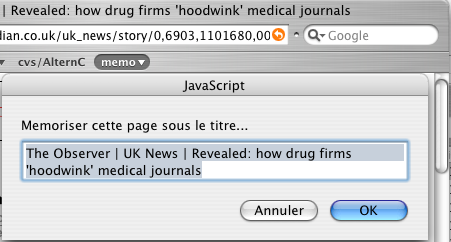
4. - On ajuste un peu...
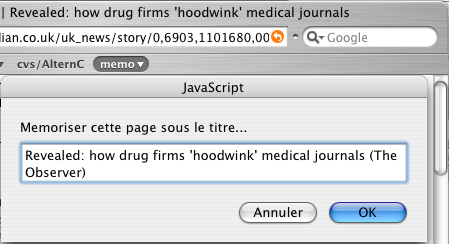
5. - Et hop !
Question : Est-ce bien légal tout ça ?
Réponse : Si vous copiez des pages web pour les republier sur votre site, sans vous soucier du droit d’auteur, vous commettez le même délit avec le « copier-coller » de votre ordinateur qu’avec ce bouton — ni plus, ni moins. Faites-en bon usage !
Discussions par date d’activité
30 discussions
Est-il possible d’avoir l’équivalent en SPIP 3,2 ?
Super outil... C’est possible de l’avoir pour SPIP 3.3 ou SPIP 3.2.7 ?
Merci.
Faut sans doute aller voir du côté du plugin Curator.
Répondre à ce message
Voila quelques modifs (remplacer les Lignes 0 à 40 avec le code ci dessous) pour que ça fonctionne à peu près en SPIP3
Ça ne fonctionne pas avec SPIP 3.1. Des pistes pour l’adapter à cette version ?
Répondre à ce message
Bonjour
Est-il prévu une mise à jour de ce petit utilitaire pour spip 2. à 3. ?
Répondre à ce message
Bonjour et bravo pour cette adaptation qui correspond à une direction importante de développement : faciliter la rapidité d’édition, dans un moment ou les outils de blogs nous donnent des habitudes de roi fénéants
A ce propos, et à titre de suggestion, j’aurai pour ma part l’utilité d’une version qui ne photocopie que la sélection en cours et non toute la page, comme on peut trouver par exemple dans le blogger.com de google.
Honnetement, je n’ai pas les compétences de développement nécessaire, j’en reste donc à un simple yaka focon ! merci d’avance !!
Bon, je me répond à moi meme : j’ai adapté un bookmarklet pour pouvoir créer rapidement des articles à partir uniquement de la sélection en cours et non de la page entière - ce qui est bien utile pour blogger avec spip, ou lorsque la page contient des menus et du texte non significatif
désolé pour le copier coller technique, ça se passe en deux étapes
A/ Modifier memo.php
B/ Modifier le lien « photocopier » (bookmarklet)
A/ Modification du code : supprimer dans memo.php les deux passages suivants
Couper ici numéro I-----------
# test version de SPIP : a partir de 1.8pr2 recuperer_page() gere le charset
if (function_exists(’init_mb_string’))
$lapage = recuperer_page($url,true) ;
else
$lapage = recuperer_page($url) ;
if (preg_match(’,<[^>]*charset=[\’" ]*([a-z0-9_-]+),i’, $lapage, $regs))
$charset = trim($regs[1]) ;
else
$charset = ’iso-8859-1’ ;
$lapage = importer_charset($lapage, $charset) ;
Fin de Couper ici nmuéro I -----------
Couper ici numéro II -----------
// TEST VALIDITE
if (sizeof($lapage) < 10)
install_debut_html(« Erreur de lecture... ») ;
echo "
burps ! Je n’ai pas réussi à lire la page
demandée (ou le résultat fait moins de 10 lignes)
:
\n
\n".nl2br(join("\n",$lapage))."\n" ;
install_fin_html() ;
exit ;
Fin de Couper ici nmuéro II -----------
B/ Modification du lien bookmarlet
Dans votre lien (bookmarklet) ajouter la mention
+’&lapage=’+escape(document.selection.createRange().text) +
à l’emplacement indiqué ci dessous
javascript:if(t=prompt(’Memoriser%20cette%20page%20sous%20le%20titre...’,document.title))%7Bvoid(location.href=’http://127.0.0.1/spip/SPIP-v1-7-2/memo.php?url=’+escape(location.href)+’&lapage=’+escape(document.selection.createRange().text) +’&rub=8&t=’+escape(t)) ;%7D
Pour info vous pouvez conserver les deux programmes (un bouton photocopier la page entière, et un bouton créer un article à partir de la sélection)
Bien sur, vous pouvez aussi avoir des boutons thématiques pour blogger directement dans la catégorie qui est pertinente
A +
Mrique / Girafe
Plutot que de supprimer tout le code de récupération de la page on peut mettre un test conditionnel :
if ($lapage==’’)
if (function_exists(’init_mb_string’))
$lapage = recuperer_page($url,true) ;
else
$lapage = recuperer_page($url) ;
if (preg_match(’,<[^>]*charset=[\’" ]*([a-z0-9_-]+),i’, $lapage, $regs))
$charset = trim($regs[1]) ;
else
$charset = ’iso-8859-1’ ;
$lapage = importer_charset($lapage, $charset) ;
S’il n’y a pas de sélection toute la page est prise en compte. On n’a donc besoin que d’un seul bouton mémo pour la sélection et pour la page entière.
Dans Firefox (netscape) le code de sélection ne marche pas
document.selection.createRange().text
il faut le remplacer par
window.getSelection()
Merci pour ce bouton bien pratique
Bonjour
j’aime l’idée de jouer sur la séléction.
Possibilité d’avoir un plugin avec cette version ?
merci
Hello fil,
tu n’envisages pas d’intégrer cette chouette fonctionnalité ?
J’ai essayé le code proposé (sous firefox) et ça marche effectivement, sauf qu’on perd toutes les fins de paragraphe !
Par ailleurs, vu qu’on ne lit plus la page d’origine mais la sélection du navigateur, on perd l’info sur le charset, ... il faudrait la lire quand même pour traduire la sélection si nécessaire ...
SVP,
Ou est-ce que on doit metre le code dans le memo.php, multicite ?
(excusez mon mauvais français)
Hola Miguel, il faut mettre le fichier à la racine du site.
Oui, je sais ; ) ... excusez moi... je m’express un peu mal...
Je parle du test conditionnel envié par multicite (cf. supra).
Dans quelle ligne du memo.php ?
Répondre à ce message
Bonjour,
Ce bouton memo a l’air très intéressant et je voudrais le tester.
Mais malheureusement je ne comprends pas comment on le configure.
Ou faut-il aller et comment faire pour le configurer ?
Quand il est dit dans le paragraphe configuration « il faut préciser dans quelle rubrique.... » Comment fait-on pour le préciser ? Ou aller ? dans un plugin particulier, dans un menu quelconque, dans un fichier ?
Si quelqu’un pouvait m’éclairer.
Il faut se rendre sur la page
http://www.ton_site.com/memo.phpBonne route !
Répondre à ce message
bonjour,
Je viens de l’installer sous Spip 2.0.10. Contrairement à Fil, je n’arrive pas à le faire marcher. La config se passe sans problème, mais quand je clique le bouton, j’obtiens :
Warning : uniqid() expects at least 1 parameter, 0 given in mon site spip sur Free/spip/ecrire/inc/distant.php on line 264
Ce problème lié à une incompatibilité de SPIP 2.0.10 avec php4 a été corrigé sur le SVN : il suffit d’ajouter mt_rand() à l’intérieur de uniqid() à la ligne citée dans le message d’erreur.
Une mise à jour du fichier ici serai bien
Répondre à ce message
Est-ce compatible spip 2 ?
Pourrais t’on imaginer un enrichissement de type « Tumblr », qui permettrait de sélectionner images, citations, vidéos..., pour intégration dans un site spip. Ce serait super cool
Donc pas compatible spip 2 visiblement
J’utilise le bouton mémo sous SPIP 2 sans souci.
Répondre à ce message
Bonjour,
Est-ce ce script importe aussi les images de l’article copié ?...
Hélas, non !
Répondre à ce message
Hello,
J’utilise beaucoup ce script, qui est formidable pour constituer une revue de presse en ligne. Il marche très bien partout,... sauf sur le site du Monde diplomatique où le script plante systématiquement (il ne met qu’un bout de titre dans la page, le champ texte reste vide).
François
Ca c’est pas banal :-)
Quand tu parles de « au milieu du titre », est-ce par hasard sur un accent ? Si oui il faut plutôt chercher du côté du charset, car le site du Diplo est en utf-8.
Peux-tu :
Hello,
J’ai testé avec une page de spip.net. Ca passe sans problème (et, si ça peut être utile, le site sur lequel j’envoie les données est en iso-latin).
Pour ce qui est du titre, j’ai systématiquement un problème (apparition de caractères chinois ou autres joyeusetés à la place des accents) avec les accents dans les titres (mais seulement là), donc ce n’est pas très embêtant et je rectifie à la main.
Quant aux pages du diplo qui ne passent pas, tous les articles sont, semble-t-il concerné. Le comportement du script mémo est soit de créer un champ texte vide (l’url est quand même sauvergardé), soit de reprendre dans le champ texte les quelques premières lignes de l’article.
Par exemple, avec la page http://www.monde-diplomatique.fr/2003/11/LATOUCHE/10651
on obtient ceci dans le champ texte :
(et les accents passent bien).
J’ai pas encore vraiment cherché dans le code d’où ça pourrait venir, je posais juste la question pour savoir si quelqu’un avait une explication. Je vais un peu farfouiller dans le code.
François
Je pense que c’est dû à un caractère non utf-8 dans un commentaire du squelette, qui fait planter la conversion utf-8 -> iso-latin.
Le bouton mémo utilisait le binaire iconv en ligne de commande ; mais maintenant SPIP sait gérer importer_charset()
Ca marche pour l’article de Serge Latouche que je citais (encodage de tout le texte, sauf le titre, qui est coupé au premier accent — mais ça c’est pas neuf).
Mais un essai sur d’autres pages (par exemple : http://www.monde-diplomatique.fr/2004/10/HALIMI/11549 ) amène le même problème que décrit ci-dessus.
François
Il faudrait confirmer ça avec la version CVS de SPIP.
C’est ce que j’ai fait. J’ai tout réinstallé, une version CVS d’il y a une heure + le script mémo tout frais téléchargé.
François
Bon, dans ce cas il faut approfondir, mais ça demande à ce que tu me contactes par mail ou sur le #spip de irc.freenode.net
Nouvelle version qui pallie partiellement ce problème — sachant que la solution véritable est de désactiver l’appel à iconv() dans inc_charsets.
La nouvelle version devrait résoudre complètement le problème ; à condition d’avoir activé mb_string dans son php, et d’avoir installé la version CVS de SPIP datée d’hier : tu peux alors même photocopier la Pravda.
Hello fil,
Pas de probleme d’accent dans le texte, mais dans le titre :
pour « photocopier » cette page, par exemple, le titre se transforme en
«
Le bouton mmo - SPIP - Contrib»A part ça, ce serait bien de pouvoir sélectionner la zone à photocopier,
soit par la sélection courante, soit par l’identifiant d’une zone (id d’un div par exemple).
Répondre à ce message
Bonsoir, :o)
juste pour dire que j’apprécie énormément de script qui m’a permit de migrer manuellement depuis la V1 de mon site perso, sans devoir tout retaper avec mes petits doigts... Et en plus, les boutons de liens restent valident qd on change de version (j’en ai fait un par rubrique à alimenter)
Merci de votre travail, j’attend impatiemment une version compatible pour 1.9.2a pour l’installer sur le site d’une amie
Cordialement :o)
Mais as-tu essayé ? Le script continue à fonctionner impeccablement sous SPIP 1.9.2 et SPIP SVN :)
J’ai fais confiance à la mention 1.9.1... :o)
Mais c’est vrai que cela fonctionne en 1.9.2a, je viens d’installer et tester...
Merci de l’info ;o)
Répondre à ce message
Apparemment, le bouton memo ne fonctionne pas sur un spip 1.9. Message : mal installé ...
???????????
Pierre N.
J’ai mis en ligne un nouveau zip qui devrait fonctionner.
Génial ! et ça fonctionne
Merci, Fil
Ah ouais c’est clair ! Merci beaucoup :D
Au début, ça m’a un peu surprit de voir que ca te copiait litéralement TOUT le texte de la page (menu et pied de page et toutes les petites portions de textes annexe à l’article) mais franchement ça te simplifie la vie ! :D
Répondre à ce message
Tout simplement merci
tres bonne contrib
et surtout utile
Répondre à ce message
merci très utile
Répondre à ce message
NB : problème évoqué par quelqu’un d’autre plus bas , mais je poste à part pour raisons de lisibilité sur ce problème spécifique
Je le rencontre ce petit problème d’acents remplacés dans le titre par des caractères chinois depuis longtemps à chaque fois que j’utilise la fonction « envoyer un lien vers cette page par mail » de mon navigateur (Firefox 1.0).
Par contre, bizarrement, la fonction « envoyer un lien vers cette page par mail » n’a jamais présenté ce défaut sous Internet Explorer.
Répondre à ce message
Bonjour,
Je tombe sur une mise à jour plus que récente !... mais :
« Utilisation : glissez le lien dans la barre des signets (...) »
je cherche veinement ce fameux lien !
Tyrien
Désolé pour le « veinement » mais je n’ai pas de « veine », je cherche en « vain »... et j’en perds mon latin.
Tyrien
Comme on n’est jamais aussi bien servi que par soi-même, voici le lien magique à insérer dans les signets (fonctionne sous SPIP 1.7.2) :
javascript:if(t=prompt('Memoriser%20cette%20page%20sous%20le%20titre...',%20document.title))+void(location.href='URL_RACINE_DE_VOTRE_SPIP/memo.php?url='+escape(location.href)+'&rub=1&t='+escape(t))Tyrien
PS. Vous me direz que le lien était indiqué dans le message précédent n°17 mais les apostrophes étaient exotiques et n’étaient pas interprétées correctement, et tous les espaces sont effectivement à éliminer. Un copier-coller direct ne devrait maintenant plus poser de problème.
Encore désolé, l’interprétation du code laisse un espace incongru à la fin de chaque ligne (trois). N’oubliez donc pas de les supprimer après le copier-coller.
Tyrien
Le lien t’est donné une fois que tu as configuré le bouton : tout en haut de la page memo.php
Apparemment certains ont un problème avec l’URL complète du site, peut-être parce qu’ils ne l’ont pas configurée dans l’espace privé ?
Répondre à ce message
pour que le bookmarklet fonctionne sous Opera (7.54 en tout cas), il convient d’effectuer quelques modifs en spécifiant, comme le notait Fil plus bas, l’URL de votre site, en mettant ’+’ en lieu et place de ’%7B’, et en effaçant le ’ ;%7D’ final :
à la base, le bookmarklet est de type (je fais des retours claviers pour faciliter la lecture, si vous copiez-collez le javascript, veuillez retirer les espaces) :
javascript:if(t=prompt(’Memoriser%20cette%20page%20sous%20le%20titre...’,
document.title))%7Bvoid(location.href=’
?url=’+escape(location.href)+’&rub=1&t=’+escape(t)) ;%7D
qu’il convient de le modifier comme suit :
javascript:if(t=prompt(’Memoriser%20cette%20page%20sous%20le%20titre...’,
document.title))+void(location.href=’
http://URL_DE_VOTRE_SPIP/memo.php
?url=’+escape(location.href)+’&rub=1&t=’+escape(t))
les problèmes d’accents demeurent, cela dit.
Répondre à ce message
l’invite de script pour le titre s’ouvre bien,
mais que neni dans la rubrique désignée,
voici ce que j’ai dans les liens
javascript:if(t=prompt(’Memoriser%20cette%20page%20sous%20le%20titre...’,document.title))%7Bvoid(location.href=’ ?url=’+escape(location.href)+’&rub=33&t=’+escape(t)) ;%7D
normal ?
en fait cela va jusqu’a l’etape 4 ajuster le titre,
mais l’etape 5 n’apparait pas
OK, je vois. C’est parce qu’il n’arrive pas à trouver l’adresse de ton site. Ajoute-là à la main dans l’URL du bouton, juste avant la partie
?url=..., tu metshttp://monsite.com/chemin/vers/memo.php?url=....Et il faudra que je corrige la détection de l’adresse...
Yessss, bien vu !
script de ouf encore ce bidule à voile !
gonflé le spi !
merci
oui effectivement il faut modifier l’adresse du bookmark à la main : à partir du paramètre ?url=... c’est bon, mais c’est l’adresse du fichier memo.php sur le site SPIP qui doit être indiquée avant ?url.
De plus, ce n’est pas vraiment à la racine du site que memo.php doit être mis, mais dans le répertoire ecrire ça marche.
Répondre à ce message
Je viens de tester le bouton mémo avec une 1.8 et cela ne passe pas.
Avec une 1.7.2 c’est bon avec la petite modif suite au commentaire de pierre le 7 janvier.
merci
Ben.
Répondre à ce message
Quand on utilise le bouton mémo, il n’y a pas de langue et donc dans SPIP il y a un ()...
Que faut-il faire pour modifier le script memo pour ajouter soit la langue par défaut ou (encore mieux) la langue de la page selon les balises HTML ?
Répondre à ce message
Voilà ce que j’obtiens :
Erreur de lecture...
burps ! Je n’ai pas réussi à lire la page demandée (ou le résultat fait moins de 10 lignes) :
Pourtant j’ai tout bien rempli le formulaire de config ...
SOS !
Répondre à ce message
Bonjour, je suis désolé d’intervenir en vous disant que ce bouton ne marche absolument pas ... dans ma config !! J’ai effectué l’installation en essayant de respecter les instructions (moyennement claires ?). Je suis sur mac os 10.2.8 et safari ...
J’ai glissé le lien dans la barre des signets, voici le lien qu’il m’a mis :
javascript:if(t=prompt(’Memoriser%20cette%20page%20sous%20le%20titre...’,document.title))%7Bvoid(location.href=’ ?url=’+escape(location.href)+’&rub=3&t=’+escape(t)) ;%7D
Bizarre, non ? (D’ailleurs, j’ai le même pb pour les noms des fichiers du cache, remplis de %20 et autres décors de ce type ...)
Bon, j’ai indiqué la rubrique 3 dans le paramétrage, oui pour activer, etc ... lorsque je clique ensuite sur le lien, « ça mouline », mais je n’ai aucun résultat visible nulle part ...???????? Si quelqu’un a une idée ? Je précise que ma base spip est installée en local ... Merci. Marc
Répondre à ce message
Bonjour jai tester cette fonctionalite en local mais ca ne semble pas marche voici mes config :
memo_active=oui
memo_status=1comite
memo_status_article=publie
memo_rubrique=6
jai change lurl genere par le script qui etait locatin.href en http://localhost/spip/memo.php...
mais je n’obtiens qu’une page blanche qd jessaie de web clipper une page d’un site
Répondre à ce message
Bonjour,
J’ai une difficulté, en dehors des accents.
Comme le script ne fonctionnait pas, j’ai suivi la recommandation de Fil et j’ai ajouté
http://monsite.com/chemin/vers/memo.php?url...(en l’occurencehttp://www.synhorcat.com/annuaire/memo.php?url....Cela fonctionne bizarrement. J’ai l’étape 1 (titre) puis cela me met directement le contenu (pas d’autres étapes) dans la rubrique concernée. Le lien hypertexte apparaît automatiquement sosu le titre et le texte se retrouve automatiquement dans le chapo.Puis une page ressemblant à sommaire-texte.php3 s’ouvre, avec une adresse comme
http://www.synhorcat.com/annuaire/sommaire.php3/ecrire/articles.php3?id_article=119La présence simultanée de
sommaire.php3suivi du répertoire « ecrire » me fait penser que le chemin est incorrect, mais je ne sais pas comment corriger ?Répondre à ce message
On dirait que Libé a contourné le machin : plus moyen de copier une page du site libe.fr avec le bouton memo. Tout le monde a ça ou c’est juste moi ?
Par ailleurs, il n’est pas possible de copier les articles de certains sites (i.e. lesoir.be) (sans doute à cause de la restriction à 10 lignes minimum de code).
Pour Libé, oui, je constate la même chose, mais il suffit d’aller sur la page « imprimer cet article » pour que ça marche. Pour Le Soir, si l’article est trop court, hein, on n’y peut rien :)
En fait c’est marrant, mais sur Libé parfois ça passe, parfois ça ne passe pas.
Pour « Le Soir », c’est n’est pas (seulement ;-) que leurs articles sont trop courts : c’est que c’est une crasse de javascript qui a l’air de virer les sauts de ligne à l’affichage.
De manière générale, memo refusera d’indexer un article provenant d’un site qui vire tous les sauts de ligne de sont code HTML.
Répondre à ce message
Bravo, vous nous proposez un outil aussi simple que pratique à utiliser et à mettre en oeuvre. J’ai quelques petit soucis avec certains caractères, mais cela reste tout de même une avancée concluante
BRAVO et ENCORE MERCI !!!
je suis d’accord, c’est super !
Répondre à ce message
Bonjour
D’abord, bravo pour l’idée & la réalisation, c’est vrai que ca devient fastidieux de tout repomper manuellement ;-))
Cela dit, j’utilise la version 1.7PR1, et je n’arrivais pas à faire fonctionner mémo.
Deux petites modifications :
- dans le javascript : attention, il y est écrit : « http://http//www.monsite.com… » ... il faut remplacer par « http://www.monsite.com »
- dans memo.php, il faut remplacer (ligne 58) : spip_fetch_array par mysql_fetch_array sans quoi on obtient un fatal error, function not defined
Bravo, en tous les cas !
Je corrige tout ça, merci !
Moi, j’ai plutôt ceci et plus rien après :(
memo_active :
« oui » pour activer le système
memo_statut :
’0minirezo’ ou ’1comite’ pour savoir qui peut mémoriser (vide = tout le monde) [pas encore implémenté]
memo_statut_article :
’publie’ si on veut publier les articles illico (admins seulement) et les indexer dans la foulée
memo_rubrique :
id_rubrique où tombent les pages mémorisées (non bloquant)
Répondre à ce message
Salut Fil,
C’est un joli script. Mais sur certaines pages que j’ai testé, les accents disparaissent. Il y a donc un problème de transcodage pour certaines pages...
Sinon, j’ai eu du mal à comprendre comment faire fonctionner le script. Une ligne pour expliquer qu’il faut utiliser le [+nomdusite] comme signet et non pas l’URL du script memo.php3 m’aurait fait perdre moins de temps.
J’espère que tu vas continuer à paufiner ce script.
un spipeur
Répondre à ce message
Waouuououo. Grandiose. Le pied du pied. C’est génial.
Euh, ça ne marche qu’en unicode ?
Non, non, c’est censé fonctionner en iso-8859-1 aussi, et être capable de lire des textes dans n’importe quel charset-source... mais parfois le titre passé par le javascript n’est pas dans le bon charset, et l’heuristique qui le « nettoie » peut se planter. Si tu as un exemple, on peut essayer de débugguer
Répondre à ce message
Très sympa ce petit script.
Quelques questions :
- Pensez-vous qu’il est possible de récupérer les notes de bas de page en format SPIP ? (en tout cas dans les sites où elles sont correctement faites). Dans la même optique, ne serait-il pas intéressant de proposer comme fonction native de spip la possibilité pour les internautes de récupérer le source spip d’un article (de façon optionnelle pour que ceux qui ne veulent pas qu’on puisse copier leur articles puissent l’empêcher. Vu la multipliction des sites sous SPIP, ça devient intéressant.
- Il serait intéressant d’améliorer l’encodage des raccourcis typographiques : espaces insécables là où c’est nécessaire notamment (j’ai pas l’impression qu’il le fait).
- Ce script ne marche pas quand on est sur une page en accès non public. Logique vu que ce n’est pas la même machine qui se connecte. Mais pensez-vous qu’il est possible de faire quelque chose de ce point de vue ?
Merci
Bonsoir Franz,
Le script a été conçu pour pouvoir mémoriser n’importe quelle page HTML contenant essentiellement du texte (un « article », publié sur un site SPIP ou non). C’est ce qui explique les imperfections dans la gestion des espaces insécables, par exemple, ou la perte de notes de bas de page : on doit partir du principe que le site que l’on mémorise n’est pas un site SPIP et essayer d’extraire de son HTML, même infâme, ce qui semble être le corps de l’article et l’insérer dans la base SPIP appellante.
Ca marche donc pour toutes les pages, mais au prix d’une certaine perte d’information (typographie, notes...). Ceci dit, tu en gagnes aussi : un article du Monde, sur leur site, n’a pas d’espaces insécables devant les « ? » ou « ! », qui sont parfois à la ligne suivante : si tu le mémorises et que tu le relis ensuite sous ton site SPIP, il est mieux présenté que l’original ;-).
Par contre, je suis entièrement d’accord avec toi sur l’utilité d’une fonction native d’exportation du source SPIP des articles : je l’avais demandé aussi mais on n’était pas encore majoritaires ;-). Ca permettrait, pour les sites non-SPIP ou n’autorisant pas cet export, d’utiliser le Mémo actuel, et de bénéficier pour les autres d’une « copie-conforme » SPIP->SPIP qui conserverait tous les raccourcis et les notes.
Par contre, rien à faire pour les pages qui ne sont pas en accès public, car en effet c’est le serveur qui héberge ton site SPIP qui transmet la requête (et qui peut difficilement s’authentifier sur le site distant). Il n’y a guère que deux solutions dans ce cas : soit patcher (salement) Mémo pour qu’il s’authentifie quand il accède à ce site-là (et encore, ça ne marche pour certains types d’authentification), soit que tu fasses une copie manuelle préalable des pages qui tu veux mémoriser dans un endroit temporaire ouvert à tous, lui. Mais pas de solution satisfaisante, non...
Amicalement,
Pierre
Pour répondre au problème des pages qui ne sont pas en accès public, ne serait-il pas possible de « saisir » le source de la page (en javascript, je sais pas si c’est possible, je crois que si) et de l’envoyer tel quel comme variable au script mémo plutôt que de n’envoyer que l’adresse et de demander ensuite à Mémo de faire le travail de butinage.
Ensuite, on crée un fichier temporaire avec le flux de données reçu et on passe ce fichier dans links (et là on est dans les traces du script tel que proposé aujourd’hui).
Sans un système de ce type, je crois que Mémo n’a pas d’intérêt pour les pages en accès restreint (parce le temps qu’il faut pour enregistrer la page, puis l’uploader sur un espace en accès public avant d’exécuter mémo, ça rend ses lettres de noblesse au bon vieux copy&paste).
Pour ce qui est des notes de bas de pages, je me disais que ce type d’information est suffisamment typé pour qu’une machine puisse les reconnaître avec quelques bonnes regex bien foutues. Mais à la réflexion, je me dis que les risques d’avoir une info éronnée ou à mointié correcte, le caractère biscornu de certains webmestres et la relative rareté des notes de bas de page (à part sur le diplo et quelques autres, mais bon) rendent finalement l’investissement en temps peu justifié.
Si Javascript est effectivement capable de mettre tout le source HTML de la page dans une variable, alors oui, pourquoi pas (mais je doute qu’il sache faire ça, et que ça marche avec tous les butineurs).
Pour les notes de bas de pages : oui, des regexp pourraient marcher, pour les sites SPIP en tout cas (pour les autres, faut pas rêver). Mais tant qu’à faire, si on veut recopier parfaitement un article SPIP, autant implémenter l’export du source de l’article...
Une rapide recherche sur le web m’indique qu’il existe une fonction
view-sourceen Javascript. J’imagine qu’elle devrait permettre de récupérer le sorce dans une variable. Je ne m’y connait pas du tout mais je veux bien essayer de creuser la question (d’ici quelques jours parce que là, j’ai pas le temps).Répondre à ce message
cela marche-t-il avec n’importe que page affichée en mode WEB, des pages WORD par-exemple ?
j’ai un SPIP en mode 1.6 que je n’ose pas faire migrer en mode 1.7b4 ayant eu des déboires après un essai.
Mais ce serait encore plus pratique que la macroword
Le bouton mémo ne lit que les mages au format HTML.
Répondre à ce message
Ajouter un commentaire
Avant de faire part d’un problème sur un plugin X, merci de lire ce qui suit :
Merci d’avance pour les personnes qui vous aideront !
Par ailleurs, n’oubliez pas que les contributeurs et contributrices ont une vie en dehors de SPIP.
Suivre les commentaires : |
|
