A propos du compilateur
Version 7 — Juin 2018 — RastaPopoulos
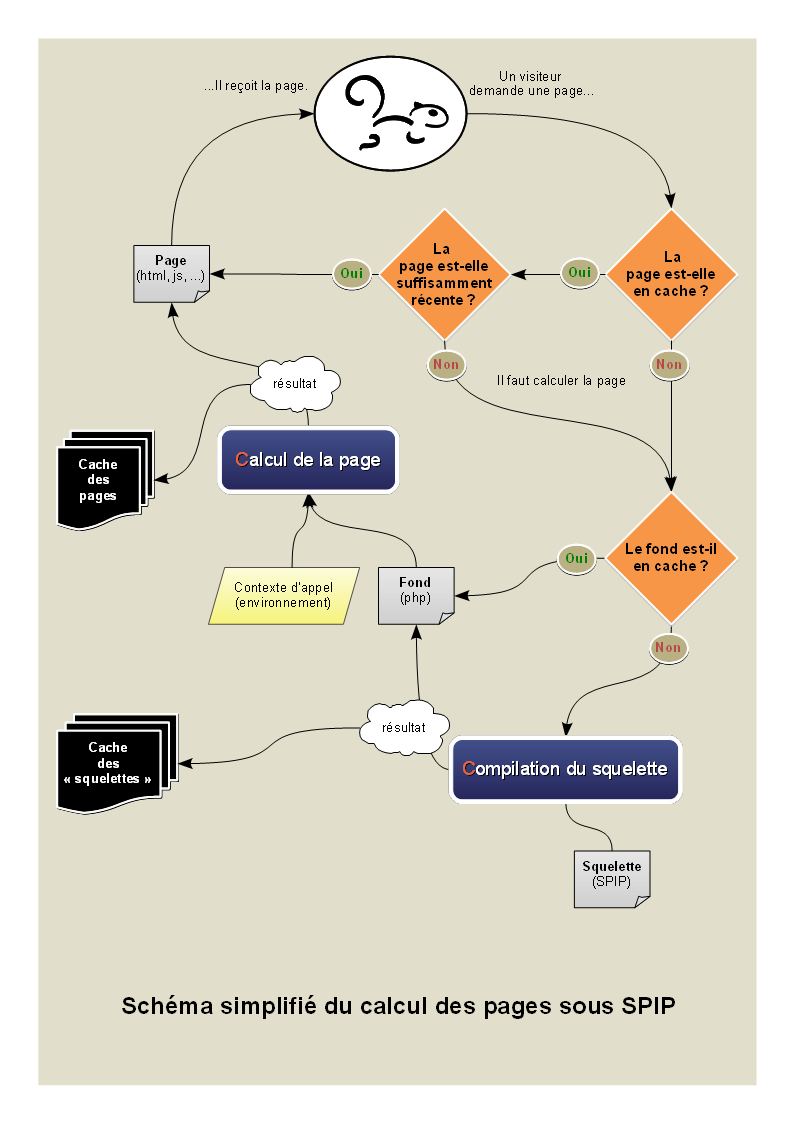
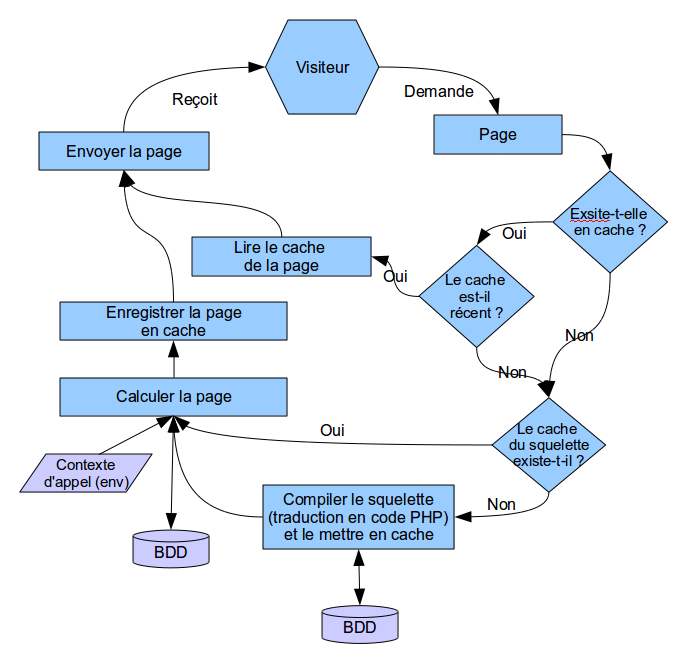
Question :
- Où est lu le squelette et où est lancé sa compilation (sa transformation en PHP), pour voir si on peut pas avoir un pipeline pour modifier le vrai squelette de départ avant sa compilation ?
Réponse (mm) :
- C’est le phraseur. La lecture se fait dans public_composer_dist() ligne 80
Question :
- Où est envoyé l’ENV pour calculer la page, pour voir si on peut ajouter un pipeline qui permet de modifier l’ENV *avant* que ça génère le HTML final ?
Exemple d’utilisation : je cherche si le squelette demandé (pas le réel fichier final trouvé, le fond demandé avant styliser) est du genre /prive/objets/liste/xxxx.htmlet dans ce cas je cherche des infos, et si ça répond à mes critères, j’ajoute "par" => "trucmuche" dans le contexte par défaut.
Réponse :
- L’env, c’est plutôt du côté de public_parametrer_dist appelé par public_produire_page_dist() lui-même appelé dans assembler()
avec $GLOBALS['contexte'] = calculer_contexte();
James : est-ce que tu as essayé dans public/assembler.Alors :
- le calcul du PHP en HTML se fait ligne 128 de parametrer . php:187:function calculer_contexte () php
- mais le nom du cache est défni bien avant
- or si on change l’ENV, il ne faut pas prendre le même cache
- pour la page complète c’est dans assembler()
- pour les inclusions c’est dans inclure_page()
Fil de discussion autour de l’ajout d’un pipeline permettant d’insérer des critères dans des boucles de squelettes précis :
http://archives.rezo.net/archives/spip-dev.mbox/GOT6AS42Z4OVQ63RM7JVIXTEORZLCWAZ/
Toutes les versions
- 13 - JLuc, Novembre 2018
- 12 - JLuc, Juin 2018
- 11 - JLuc, Juin 2018
- 10 - RastaPopoulos, Juin 2018
- 9 - JLuc, Juin 2018
- 8 - 78.242.xx.xx, Juin 2018
- 7 - RastaPopoulos, Juin 2018
- 6 - RastaPopoulos, Juin 2018
- 5 - RastaPopoulos, Juin 2018
- 4 - JLuc, Juin 2018
- 3 - RastaPopoulos, Juin 2018
- 2 - JLuc, Juin 2018
- 1 - JLuc, Version initiale