Evolution du plugin Bouquinerie
Version 15 — Février 2017 — 84.127.xx.xx
Cet article est destiné aux personnes interessées par l’évolution du plugin Bouquinerie pour SPIP 3.
N’hésitez pas à ajouter vos remarques et contributions dans le dernier paragraphe, l’article est librement éditable.
Vous pouvez également suivre le fil de discussion sur la liste spip.users : http://archives.rezo.net/archives/spip.mbox/RNCMG3KDBWETD4CEA4N43WYXAP62SX5T/
Que vous soyez utilisateurs ou non, contribuez à la discussion !
La version courante (0.1.0) n’est pas compatible SPIP 3, et le plugin a peu évolué depuis son dépôt sur la zone.
Je souhaite me charger de sa mise à jour.
Plutôt que de faire un « simple » portage pour SPIP 3, profitons-en pour faire une remise à plat : à qui se destine le plugin ? De quelles fonctionnalités a-t-on besoin ?
Mise à jour du 18/09/2014
Un prototype est dispo : téléchargement.
Attention, il s’agit d’une version de développement, il n’y a pas encore de gestion des groupes de livres et l’interface n’est pas finie. De plus, ce prototype n’est pas compatible avec le plugin stable.
Pour l’instant on eut :
- créer des éditeurs
- créer des livres
- importer des livres automatiquement depuis google book
- associer des livres aux objets.
Le plugin actuel (version .1.0 pour SPIP 2)
Etat des lieux / récapitulatif succint :
- Le plugin a été conçu à destinations des librairies/bouquineries, pour leur permettre de présenter des catalogues de livres (neufs et occasions) à l’achat et à la vente.
- Dans l’espace privé, il permet la gestion de «
livres» qu’on regroupe sous formes de «catalogues», les 2 étant de nouveaux objets éditoriaux. - Un formulaire permet d’importer des catalogues provenant du site commercial « Priceminister ».
- Des squelettes sont fournis pour le site publique.
Problèmes soulevés :
- Le plugin n’est pas vraiment adpaté à la gestion de collections de livres dans un cadre non commercial : maisons d’édition ou particuliers par exemple.
Concrètement, la table «spip_livres» comporte de nombreux champs pertinents uniquement dans le cadre d’un commerce : «etat_livre», «etat_jaquette», «prix_achat», «commentaire», «num_facture» etc. - Le regroupement des livres sous formes de « catalogues » est imposé.
- Le nom, l’adresse de la boutique, les mentions légales etc. sont enregistrés dans les options de configuration du plugin.
- Gestion technique dans l’espace privé + squelettes pour le site publique = mélange des genres !
Proposition d’évolution (version 1.x pour SPIP 3)
Dernière m.a.j : 23/04/2014
Je propose de ne garder dans Bouquinerie que l’aspect « gestion de collections de livres », et de basculer les fonctions typées commerce dans un plugin tiers, qui servirait d’extension au premier.
Ainsi le plugin serait plus générique et utilisable par un plus large public : les librairies, mais également les particuliers, les maisons d’édition, et pourquoi pas les bibliothèques.
Essentiellement, le plugin permettra de créer des « livres », que l’on pourra classer en séries, collections, catalogues etc. Il permettra l’importation de livres par le biais de recherches dans des bases de données en ligne (google books, open library etc.).
Bref il s’agira d’une rupture de compatibilité assumée avec la version pour SPIP 2 : du moment que c’est les changements sont bien documentés ça me semble jouable.
Livres : champs proposés
Je propose de faire le ménage dans la table spip_livres.
Y a-t-il des champs à ajouter ?
| Nom | explication | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
#TITRE |
Tire du livre | ||||||||||||
#ISBN |
Numéro ISBN à 10 ou 13 chiffres. On pourrait si besoin séparer en 2 champs distincts : #ISBN_10 et ISBN_13 | ||||||||||||
#IDENTIFIANT |
Identifiant unique optionnel. Typiquement, il est donné par les base de données en ligne (google books et cie). Permet d’éviter les doublons lors de l’importation de nouveaux livres. | ||||||||||||
#DATE_PARUTION |
Date de parution | ||||||||||||
#LANG |
Langue du livre, code ISO-639-1 à 2 lettres (idem code langue SPIP) | ||||||||||||
#VOLUME (ou bien #TOME ?) |
Numéro du livre au sein d’une série | ||||||||||||
#PAGES |
Nombre de pages | ||||||||||||
#HAUTEUR |
Hauteur en cm | ||||||||||||
#LARGEUR |
Largeur en cm | ||||||||||||
| <code>#EDITION_NUMERIQUE</code > | oui/non edition numerique | < code>#EDITION_PAPIER</code > | oui/non edition papier | < code>#PRIX_NUMERIQUE</code > | Prix edition numerique | < code>#PRIX_PAPIER</code > | Prix edition papier | < code>#DESCRIPTIF | Descriptif du livre (par ex. 4e de couverture) | ||||
#TEXTE |
Extrait du texte | ||||||||||||
#ID_RUBRIQUE & #ID_SECTEUR (pas sûr) |
Eventuellement, identifiant de la rubrique et du secteur pour permettre d’y « ranger » les livres. |
Gestion des statuts
Pas encore défini, quel satuts sont souhaitables ? Peut-être « réédité », « épuisé », ce genre de chose ?
A défaut, on va sans doute revenir aux statuts de base « en cours de rédaction », « publié » et « à la poubelle ».
Je serais d’accord pour rajouter le statut « épuisé » (à la place du satut « refusé » de SPIP
Gestion des auteurs
Utilisation de l’objet « auteur » de SPIP, en ajoutant la gestion des rôles par le biais du plugin rôles de M.Marcillaud (cf. la vidéo de démonstration).
Les rôles seront prédéfinis, voici la liste (à compléter) :
- rédacteur (ou écrivain ?) : rôle par défaut
- traducteur
- relecteur
- correcteur
- illustrateur
- préfacier
- postfacier
Gestion des éditeurs
Ajout d’un nouvel objet éditorial « éditeur ».
La table spip_editeurs comprend les champs suivants :
| #NOM | Nom de l’éditeur |
| #DESCRIPTIF | Descriptif rapide |
| #TEXTE | Présentation détaillée |
Gestion des groupes : séries, collections, etc.
Assurément un des points les plus importants : on doit avoir la possibilité de classer les livres de façon simple en définissant des groupes : des « séries », des « collections » etc.
Cela sera possible de plusieurs façons :
1) Gestion de groupe de livres : ajout d’un objet éditorial conteneur dont le rôle est de constituer des groupes de livre. Dans la version pour SPIP 1.x, on parle de « cataogue », peut-être que le terme « groupe_livres » sera plus approprié, à voir. Un groupe aura les champs : #TYPE, #TITRE, #DESCRIPTIF.
| #TYPE | type de groupe : série, collection, catalogue... |
| #TITRE | titre du groupe |
| #DESCRIPTIF | descriptif rapide |
Ex : après avoir crée le livre « Les naufragés du A », on l’associe au catalogue de type : « série », titre : « Philémon », descriptif : « Les albums de Philémon ».
2) Liaisons : on pourra ajouter des livres à tout type d’objet éditorial par le biais de la table de liens spip_livres_liens. Il sera donc possible de « ranger » livres en les liants à des rubriques par exemple.
3) Mots-clés : utilisation des mot-clés
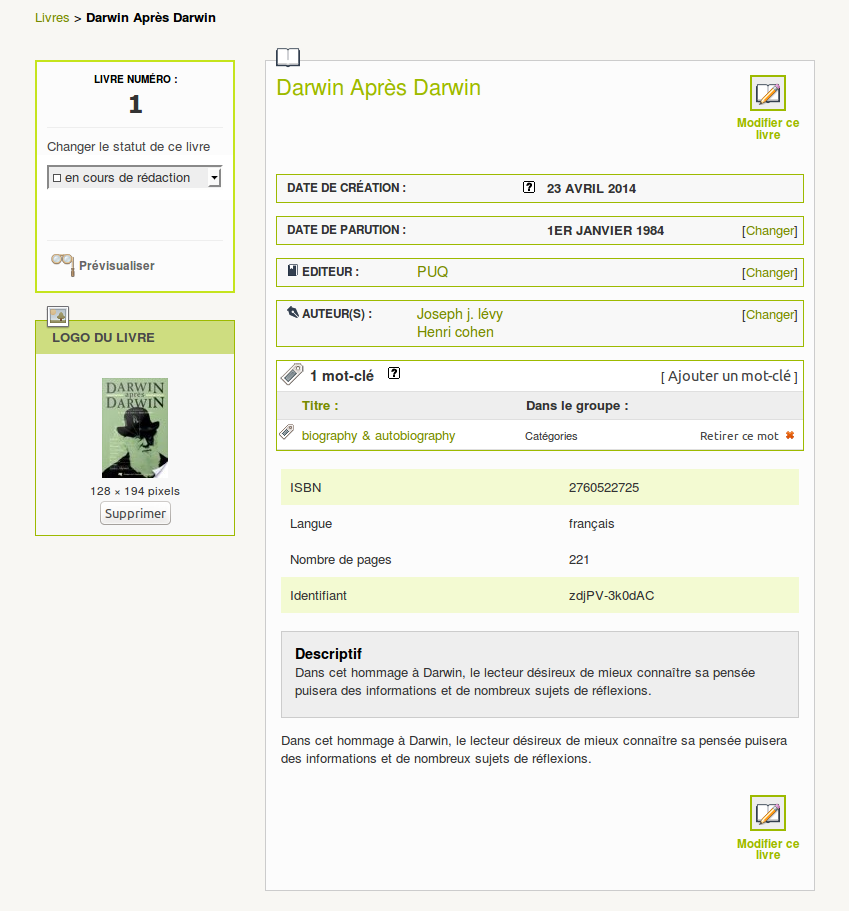
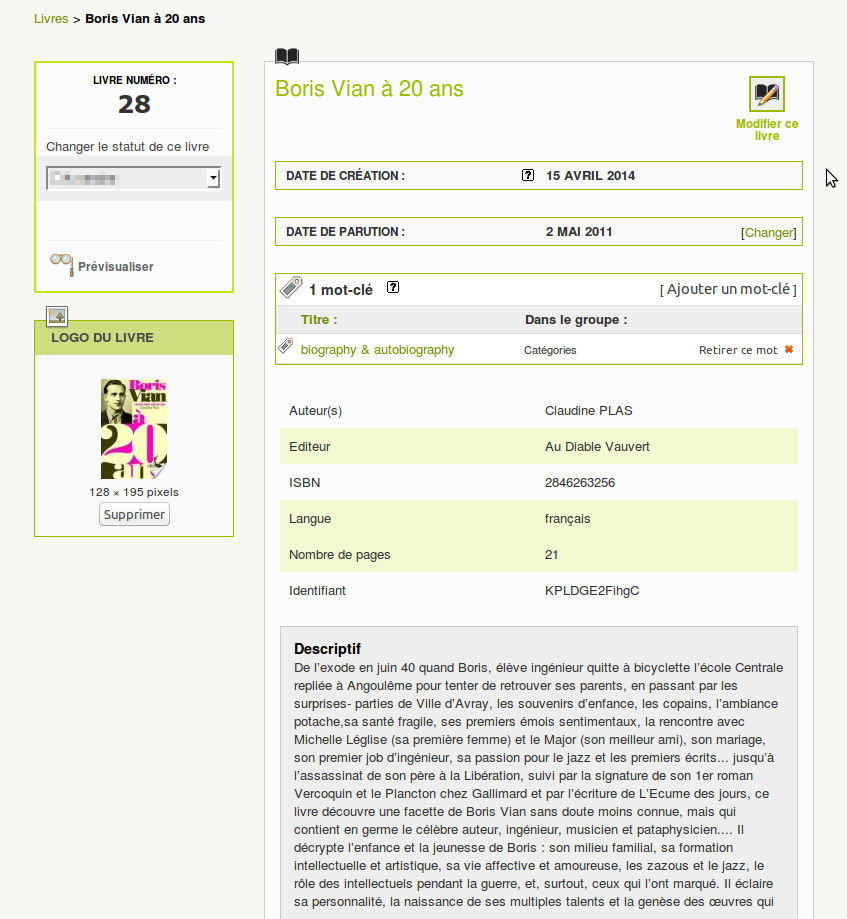
Livres : importation/exporation
On peut importer un ou plusieurs livres à la fois en faisant une recherche en ligne (sur google books, open library etc.) directement dans l’espace privé.
Pour l’export, c’est à voir : existe-t-il un format standard ?


Vos remarques & contributions ici
Peetdu
Livres : champs proposés
- en plus de l’ISBN10 et ISBN13, il faudrait sans doute rajouter l’EAN-13
- Hauteur et largeur : on trouve plutôt un seul champ FORMAT = 21 x 25,5 sur les sites editeurs et libraires
- archi d’accord pour les champs #ID_RUBRIQUE et #ID_SECTEUR. Pouvoir ranger les bouquins dans des rubriques me semble une option très bien dans beaucoup de cas.
J’ajouterais également les champs suivants
#POIDS |
poids en grammes |
#EXTRAIT |
extrait du livre : champ texte avec barre de raccourcis typo réduite ? |
#CLIL |
le code Thème CLIL. Voir plugin SPIP à cet effet. Donc optionnel |
Gestion des statuts
Je serais d’accord pour rajouter le statut « épuisé » (à la place du satut « refusé » de SPIP), cela en plus de « en cours de rédaction », « publié » et « à la poubelle ».
Gestion des auteurs
Oui pour l’utilisation des rôles !!!
Je pense toutefois qu’il ne faut pas utiliser l’objet auteurs de SPIP. Car il ajouterais automatiquement le nom du rédacteur de la fiche livre et celui-ci n’a rien à faire à côté de l’auteur, traducteur, illustrateur, etc. du livre.
Dans un projet similaire, j’ai fait un objet « auteur_livre » avec des rôles.
Où alors éviter de rajouter le rédacteur comme auteur,et faire un set_request(’id_auteur’,’’) dans le traiter.
Mais du coup on perd l’affectation d’une fiche livre à son rédacteur SPIP.
- rédacteur (ou écrivain ?) : rôle par défaut -> non il s’agit ici de l’auteur du livre. Il est important de garder la bonne terminologie.
Toutes les versions
- 16 - 153.228.xx.xx, Août 2017
- 15 - 84.127.xx.xx, Février 2017
- 14 - Peetdu, Décembre 2016
- 13 - Peetdu, Janvier 2016
- 12 - 88.162.xx.xx, Janvier 2016
- 11 - tcharlss, Février 2015
- 10 - 109.190.xx.xx, Septembre 2014
- 9 - tcharlss, Avril 2014
- 8 - tcharlss, Avril 2014
- 7 - tcharlss, Avril 2014
- 6 - 109.190.xx.xx, Avril 2014
- 5 - tcharlss, Avril 2014
- 4 - 92.139.xx.xx, Avril 2014
- 3 - tcharlss, Avril 2014
- 2 - tcharlss, Avril 2014
- 1 - tcharlss, Version initiale