
Allez, avouez... il ne vous est jamais arrivé d’avoir besoin d’articles qui ne sont rattachés à aucun rubriquage particulier ? Des articles uniques, n’ayant ni de thème, ni de rapport avec aucun autre ? Ou encore des articles pour lesquels vous avez besoin de faire un squelette particulier mais dont le contenu doit rester modifiable classiquement dans l’interface privée ?
Des pages, en quelque sorte. Des pages uniques rattachées à rien.
On a tous utilisé des bidouilles devenues des habitudes, que ce soit en se basant sur des mots-clés « techniques » ou bien en créant une rubrique « fourre-tout » que l’on devait ensuite rendre invisible dans tous nos squelettes en mettant {id_rubrique!=1}, par exemple.
Ce plugin propose de faire tout cela de manière plus propre et plus pratique.
On peut alors l’utiliser pour créer des pages de notice légale, d’à-propos, ou encore de contact.
Créer des pages
Le plugin ajoute une entrée « Pages uniques » dans le menu « Édition ».
On arrive sur une liste des pages déjà créées. Avec un lien permettant d’en ajouter de nouvelles.
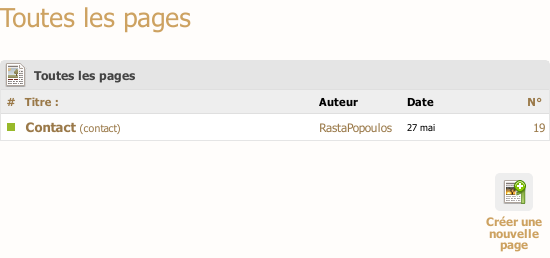
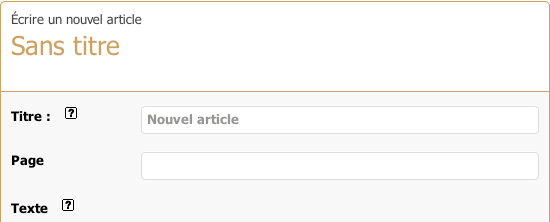
Le formulaire de création d’une page est le même que celui d’un article. Sauf qu’on n’a pas à choisir de rubrique. À la place, on désigne un identifiant de page.
Afficher les pages sur son site
Les pages sont des articles comme les autres, ils n’ont simplement pas de rubrique.
Vous pouvez donc :
- Utiliser une boucle classique
<BOUCLE_art(ARTICLES){id_article=38}>#URL_ARTICLE</BOUCLE_art> - Utiliser les raccourcis dans les textes
[->art38] - Cela utilisera donc le squelette normal « article.html »
Mais les pages uniques ont aussi un champ « page » ! Qui peut être utilisé de plusieurs manières pour récupérer habilement ses pages.
Imaginons que l’on ait créé une page « Notice légale » avec le mot « legal » dans le champ « page ». On peut alors :
- Faire une boucle
<BOUCLE_legal(ARTICLES){page=legal}>#TEXTE</BOUCLE_legal> - Avoir un squelette « legal.html » dédié. Comme ce squelette sera appelé par
?page=legal, le critère{page=legal}peut se simplifier, dans ce squelette, et s’écrire simplement{page}. La boucle principale devient alors simplement :<BOUCLE_legal(ARTICLES){page}> - Depuis la version 1.5.1, il est possible d’avoir un squelette dédié « article=legal.html » qui sera utilisé automatiquement avec la vraie URL de l’article. Ainsi vous pouvez avoir des belles adresses propres tout en ayant un squelette dédié, et sans avoir à utiliser Compositions pour juste un article. Cela fonction aussi avec Z-core pour le squelette du bloc principal.
Lorsqu’on veut juste l’URL, il existe aussi la balise #URL_PAGE_UNIQUE{identifiant} qui permet de retourner l’#URL_ARTICLE mais depuis l’identifiant textuel donné à la page.
Remarques techniques : conséquence sur les boucles (ARTICLES)
Les pages uniques sont automatiquement exclues des boucles (ARTICLES) sauf si l’un des critères suivant est présents :
-
{tout}; -
{page}avec éventuellement des opérateurs ({page=toto}, sauf{page=''}; -
{id_rubrique=-1}ou{id_rubrique<0} -
{id_rubrique}ou{id_rubrique?avec une rubrique égale à -1 dans l’environnement ; -
{id_article}avec éventuellement des opérateurs : -
{traduction}et{origine_traduction}avec éventuellement des opérateurs.
Discussions par date d’activité
104 discussions
Bonjour,
Avec SPIP 3.2.8, la recherche dans l’espace privé (ecrire) de SPIP ne permet pas de trouver une page unique, que ce soit par un mot de son titre ou par son identifiant numérique.
Ça fait donc des pages uniques un des rares objet de SPIP que la recherche intégrée à l’admin ne trouve pas.
Un moyen de corriger ça ? (genre un filtre via le pipeline pre_boucle pour que ça ne soit plus exclus) ?
Bah c’est justement dans pre_boucle qu’on l’exclu maintenant des boucles ARTICLES par défaut. Et dans la recherche, ça appelle les listes d’objets *par défaut* de chaque objet, donc pour les articles, une boucle ARTICLES par défaut, donc c’est exclu.
Pour que ça y soit dans la page de résultats recherche, il faudrait dans un pipeline rajouter un *autre* bloc de liste d’articles différents, avec spécifiquement les pages uniques dedans, en passant le GET « recherche » qu’on trouve dans le contexte. Ça doit pas être super compliqué. Un ticket au moins plutôt ?
Donc, c’est ici que ça se passe : https://git.spip.net/spip-contrib-extensions/pages/src/branch/master/pages_pipelines.php#L333
Est-ce qu’il serait envisageable de rajouter une exception de plus : si on est dans le privé, dans la page recherche, alors on ne filtre pas les pages uniques.
Ou, mieux encore, faire prendre en compte dans la page de recherche, le squelette https://git.spip.net/spip-contrib-extensions/pages/src/branch/master/prive/objets/liste/pages.html
Je suis sur le coup !
J’ai fait une PR si tu peux jeter un œil : https://git.spip.net/spip-contrib-extensions/pages/pulls/6
Répondre à ce message
Bonjour,
SPIP 3.3.0-dev [24547] et Pages 1.4.0.
Avec l’interface privé de SPIP qui évolue en largeur (et autres), il y a quelque chose qui a bougé pour Pages uniques depuis les derniers commits de SPIP : quand on entre en modification d’une page, le remplacement du texte « Modifier cet article » dans « entete-formulaire » ne se fait plus correctement. Du coup, le titre se trouve affiché en une colonne étroite.
Le REGEX dans $cherche ligne 40 de pages_pipelines.php ne cherche plus correctement sa cible ;-)
Ça a été modifié par Marcimat ici à priori :
https://git.spip.net/spip-contrib-extensions/pages/commit/369e1ef10133c210a9ebc999f389679c1d4b9c90
La modification de @marcimat date du 28 août 2020 et se retrouve dans la v1.5.3, mais la version dispo via SVP est la v1.5.2.
https://git.spip.net/spip-contrib-extensions/pages/commit/369e1ef10133c210a9ebc999f389679c1d4b9c90
Ceci dit : merci @RastaPopoulos et @marcimat ;-)
Je viens de dire de generer la bonne version pour svp. Devrait être dispo bientot.
C’est sympa @Maïeul
Répondre à ce message
Bonjour,
J’ai une difficulté avec ce plugin.
L’installation du plugin se déroule normalement.
Mais, quand je veux créer une page unique, j’obtiens le message d’erreur suivant :
Message :
Erreur SQL 1054
Unknown column ’page’ in ’field list’
SELECT page FROM spip_articles WHERE id_article=0
Squelette :
/home/xxxx/www/plugins/pages/pages_pipelines.php
Boucle :
pages_affiche_hierarchie() sql_getfetsel() ;
Ligne :
310
Quelqu’un serait-il en mesure de m’aider ?
Si tu as Unknown column ’page’ c’est que le champ est pas là à priori, donc que le plugin ne s’est pas installé
Merci pour votre réponse.
C’est étrange, car je l’ai installé et ré-installé plusieurs fois et les messages d’erreurs sont toujours là.
L’installation se déroule correctement (message selon lequel le plugin a été installé avec succès).
j’ai également essayé de voir s’il ne s’agit pas d’un problème d’interférence avec un autre plugin, mais les messages demeurent quand je désactive tous les plugins sauf Pages.
Pourrait-il s’agir d’une incompatibilité avec la version de spip (3.2.7) + écran de sécurité 1.3.13 ?
Voici les différents messages que j’obtiens :
1,- Quand je clique sur « créer une nouvelle page », cela donne le message suivant :
Message : Erreur SQL 1054 Unknown column ’page’ in ’field list’ SELECT page FROM spip_articles WHERE id_article=0 / Squelette : /home/xxxx/www/plugins/pages/pages_pipelines.php / Boucle : pages_affiche_hierarchie() sql_getfetsel() ; / Ligne : 310
2.- Quand je clique sur un article déjà publié (dans l’espace privé), apparaissent les trois messages suivants :
Message : Erreur SQL 1054 Unknown column ’page’ in ’field list’ SELECT page FROM spip_articles WHERE id_article=11 / Squelette : /home/xxxx/www/plugins/pages/pages_pipelines.php / Boucle : pages_affiche_hierarchie() sql_getfetsel() ; / Ligne : 310
Message : Erreur SQL 1054 Unknown column ’page’ in ’field list’ SELECT page FROM spip_articles WHERE id_article=11 / Squelette : /home/xxxx/www/plugins/pages/pages_pipelines.php / Boucle : pages_boite_infos() sql_getfetsel() ; / Ligne : 281
Message : Erreur SQL 1054 Unknown column ’page’ in ’field list’ SELECT page FROM spip_articles WHERE id_article=11 / Squelette : /home/nicolasfzc/www/plugins/pages/pages_pipelines.php / Boucle : pages_affiche_milieu_identifiant() sql_getfetsel() ; / Ligne : 83
Oui bah c’est que le même message quoi. Mais donc tu l’as ce champ « page » dans la table articles ou pas ?
Je suis désolé, je ne sais pas ce qu’est la « table articles ».
Quand je clique dans « Articles » du menu « Édition » de l’espace privé, aucun message d’erreur n’apparaît.
En revanche, quand je clique sur l’un des articles publié, les 3 messages exposés ci-dessus (cf,- 2-) apparaissent. Quand je clique sur « écrire un nouvel article », c’est le même message que celui qui apparait en cas de création d’une « nouvelle page » (cf. 1,- ci-dessus) .
Les « tables » sont les structures dans laquelle SPIP stocke les données. Normalement, un utilisateur lambda ne s’en préoccupe pas. Mais précisement là il y a eu un souci au niveau de la structure, et c’est ce qui cause les soucis que tu as.
Bref, pour y voir plus clair, pourrait tu :
- repasser dans la page de gestion des plugins, déinstaller (et pas désactiver) le plugins, puis réinstaller, puis nous fournir le contenu du fichier
mysql.logque tu dois pouvoir récuperer via ftp danstmp/log- regarder avec PHP my admin (qui est fourni normalement avec ton hébergeur, tout dépend de celui-ci) la table
spip_articleset nous indiquer la structure.Voici le contenu du fichier mysql.log :
2020-05-08 10:15:05 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 10:15:06 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L281 [sql_getfetsel(),pages_boite_infos(),call_user_func(),minipipe(),execute_pipeline_boite_infos(),pipeline(),BOUCLE_navhtml_33ae2615afb707e372e162aa1eb66404(),html_33ae2615afb707e372e162aa1eb66404(),public_parametrer_dist(),public_produire_page_dist(),inclure_page(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 10:15:06 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L83 [sql_getfetsel(),pages_affiche_milieu_identifiant(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 10:15:07 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L27 [sql_getfetsel(),pages_affiche_milieu_ajouter_page(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),traiter_appels_inclusions_ajax()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 11:14:14 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:14 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L281 [sql_getfetsel(),pages_boite_infos(),call_user_func(),minipipe(),execute_pipeline_boite_infos(),pipeline(),BOUCLE_navhtml_33ae2615afb707e372e162aa1eb66404(),html_33ae2615afb707e372e162aa1eb66404(),public_parametrer_dist(),public_produire_page_dist(),inclure_page(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:14 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L83 [sql_getfetsel(),pages_affiche_milieu_identifiant(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:15 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L27 [sql_getfetsel(),pages_affiche_milieu_ajouter_page(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),traiter_appels_inclusions_ajax()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:36 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-08 11:20:01 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 19193) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-08 16:03:21 2a01:e0a:521:4e30:8903:a040:3ba8:7ae2 (pid 28118) :Pri:ERREUR : Erreur 1091 de mysql : Can’t DROP ’page’ ; check that column/key exists
in /home/nicolasfzc/www/plugins/pages/pages_administrations.php L53 [sql_alter(),pages_vider_tables(),spip_plugin_install(),plugins_installer_dist(),do_stop(),do_action(),one_action(),action_actionner_dist(),traiter_appels_actions()]
ALTER TABLE
nicolasfzck.spip_articles DROP page2020-05-08 16:04:55 2a01:e0a:521:4e30:8903:a040:3ba8:7ae2 (pid 28118) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-08 16:05:00 2a01:e0a:521:4e30:8903:a040:3ba8:7ae2 (pid 28118) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
Est tu bien passé par la page de gestion des plugins ?
Oui. J’ai désinstallé et réinstallé le plugin dans la page de gestion des plugins
Désinstallé, pas désactivé ? ce sont 2 choses différentes.
Oui désinstallé. Je peux recommencer si nécessaire.
Voici la structure de spip_articles :
1 id_articlePrimaire bigint(21) Non Aucun(e) AUTO_INCREMENT Modifier Modifier Supprimer Supprimer
Plus Plus
2 surtitre text utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
3 titre text utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
4 soustitre text utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
5 id_rubriqueIndex bigint(21) Non 0 Modifier Modifier Supprimer Supprimer
Plus Plus
6 descriptif text utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
7 chapo mediumtext utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
8 texte longtext utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
9 ps mediumtext utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
10 dateIndex datetime Non 0000-00-00 00:00:00 Modifier Modifier Supprimer Supprimer
Plus Plus
11 statutIndex varchar(10) utf8_general_ci Non 0 Modifier Modifier Supprimer Supprimer
Plus Plus
12 id_secteurIndex bigint(21) Non 0 Modifier Modifier Supprimer Supprimer
Plus Plus
13 maj timestamp Oui NULL Modifier Modifier Supprimer Supprimer
Plus Plus
14 export varchar(10) utf8_general_ci Oui oui Modifier Modifier Supprimer Supprimer
Plus Plus
15 date_redac datetime Non 0000-00-00 00:00:00 Modifier Modifier Supprimer Supprimer
Plus Plus
16 visites int(11) Non 0 Modifier Modifier Supprimer Supprimer
Plus Plus
17 referers int(11) Non 0 Modifier Modifier Supprimer Supprimer
Plus Plus
18 popularite double Non 0 Modifier Modifier Supprimer Supprimer
Plus Plus
19 accepter_forum char(3) utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
20 date_modif datetime Non 0000-00-00 00:00:00 Modifier Modifier Supprimer Supprimer
Plus Plus
21 langIndex varchar(10) utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
22 langue_choisie varchar(3) utf8_general_ci Oui non Modifier Modifier Supprimer Supprimer
Plus Plus
23 id_tradIndex bigint(21) Non 0 Modifier Modifier Supprimer Supprimer
Plus Plus
24 nom_site tinytext utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
25 url_site text utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
26 virtuel text utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
27 composition varchar(255) utf8_general_ci Non Modifier Modifier Supprimer Supprimer
Plus Plus
28 composition_lock tinyint(1) Non 0
J’ai recommencé une nouvelle fois l’opération (désinstallation du plugin dans la page de gestion des plugins).
Voici le résultat du fichier mysql,log :
2020-05-08 10:15:05 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 10:15:06 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L281 [sql_getfetsel(),pages_boite_infos(),call_user_func(),minipipe(),execute_pipeline_boite_infos(),pipeline(),BOUCLE_navhtml_33ae2615afb707e372e162aa1eb66404(),html_33ae2615afb707e372e162aa1eb66404(),public_parametrer_dist(),public_produire_page_dist(),inclure_page(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 10:15:06 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L83 [sql_getfetsel(),pages_affiche_milieu_identifiant(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 10:15:07 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 29457) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L27 [sql_getfetsel(),pages_affiche_milieu_ajouter_page(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),traiter_appels_inclusions_ajax()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-08 11:14:14 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:14 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L281 [sql_getfetsel(),pages_boite_infos(),call_user_func(),minipipe(),execute_pipeline_boite_infos(),pipeline(),BOUCLE_navhtml_33ae2615afb707e372e162aa1eb66404(),html_33ae2615afb707e372e162aa1eb66404(),public_parametrer_dist(),public_produire_page_dist(),inclure_page(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:14 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L83 [sql_getfetsel(),pages_affiche_milieu_identifiant(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:15 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L27 [sql_getfetsel(),pages_affiche_milieu_ajouter_page(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),traiter_appels_inclusions_ajax()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-08 11:14:36 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 1270) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-08 11:20:01 2a01:e0a:521:4e30:d819:cc6d:1b89:707 (pid 19193) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-08 16:03:21 2a01:e0a:521:4e30:8903:a040:3ba8:7ae2 (pid 28118) :Pri:ERREUR : Erreur 1091 de mysql : Can’t DROP ’page’ ; check that column/key exists
in /home/nicolasfzc/www/plugins/pages/pages_administrations.php L53 [sql_alter(),pages_vider_tables(),spip_plugin_install(),plugins_installer_dist(),do_stop(),do_action(),one_action(),action_actionner_dist(),traiter_appels_actions()]
ALTER TABLE
nicolasfzck.spip_articles DROP page2020-05-08 16:04:55 2a01:e0a:521:4e30:8903:a040:3ba8:7ae2 (pid 28118) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-08 16:05:00 2a01:e0a:521:4e30:8903:a040:3ba8:7ae2 (pid 28118) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-11 11:30:34 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 15568) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
2020-05-11 11:30:50 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 15568) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-11 11:30:50 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 15568) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L281 [sql_getfetsel(),pages_boite_infos(),call_user_func(),minipipe(),execute_pipeline_boite_infos(),pipeline(),BOUCLE_navhtml_33ae2615afb707e372e162aa1eb66404(),html_33ae2615afb707e372e162aa1eb66404(),public_parametrer_dist(),public_produire_page_dist(),inclure_page(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-11 11:30:51 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 15568) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L83 [sql_getfetsel(),pages_affiche_milieu_identifiant(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-11 11:30:51 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 15567) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L27 [sql_getfetsel(),pages_affiche_milieu_ajouter_page(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),traiter_appels_inclusions_ajax()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=11
2020-05-11 11:36:28 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 29513) :Pri:ERREUR : Erreur 1091 de mysql : Can’t DROP ’page’ ; check that column/key exists
in /home/nicolasfzc/www/plugins/pages/pages_administrations.php L53 [sql_alter(),pages_vider_tables(),spip_plugin_install(),plugins_installer_dist(),do_stop(),do_action(),one_action(),action_actionner_dist(),traiter_appels_actions()]
ALTER TABLE
nicolasfzck.spip_articles DROP page2020-05-11 11:37:10 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 29513) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=0
Oui comme dit depuis le début, l’installation ne s’est pas faite réellement et tu n’as pas le champ « page » ajouté dans la table des articles.
Ta copies de mysql.log n’aide pas car ça ne montre que l’après, une fois que tu vas sur des pages et que ça bug car il manque le champ.
Il faut le log mysql directement juste après l’installation. C’est-à-dire totalement désinstaller le plugin, puis supprimer ces fichiers de log, puis installer le plugin et ne RIEN aller ailleurs, directement regarder les logs juste après l’installation. Normalement si MySQL a planté un truc pendant, on devrait le voir.
Voici le résultat :
2020-05-11 11:52:58 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 11108) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L310 [sql_getfetsel(),pages_affiche_hierarchie(),call_user_func(),minipipe(),execute_pipeline_affiche_hierarchie(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-11 11:52:58 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 11108) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L281 [sql_getfetsel(),pages_boite_infos(),call_user_func(),minipipe(),execute_pipeline_boite_infos(),pipeline(),BOUCLE_navhtml_33ae2615afb707e372e162aa1eb66404(),html_33ae2615afb707e372e162aa1eb66404(),public_parametrer_dist(),public_produire_page_dist(),inclure_page(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-11 11:52:58 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 11108) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L83 [sql_getfetsel(),pages_affiche_milieu_identifiant(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),evaluer_fond(),recuperer_fond(),eval(),include(),include()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-11 11:52:58 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 11108) :Pri:ERREUR : Erreur 1054 de mysql : Unknown column ’page’ in ’field list’
in /home/nicolasfzc/www/plugins/pages/pages_pipelines.php L27 [sql_getfetsel(),pages_affiche_milieu_ajouter_page(),call_user_func(),minipipe(),execute_pipeline_affiche_milieu(),pipeline(),f_afficher_blocs_ecrire(),f_recuperer_fond(),call_user_func(),minipipe(),execute_pipeline_recuperer_fond(),pipeline(),recuperer_fond(),traiter_appels_inclusions_ajax()]
SELECT page
FROM
nicolasfzck.spip_articlesWHERE id_article=14
2020-05-11 11:56:09 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 4551) :Pri:ERREUR : Erreur 1091 de mysql : Can’t DROP ’page’ ; check that column/key exists
in /home/nicolasfzc/www/plugins/pages/pages_administrations.php L53 [sql_alter(),pages_vider_tables(),spip_plugin_install(),plugins_installer_dist(),do_stop(),do_action(),one_action(),action_actionner_dist(),traiter_appels_actions()]
ALTER TABLE
nicolasfzck.spip_articles DROP pageNon mais là tu vois bien que c’est toujours la même erreur « Unknown column ’page’ in ’field list’ », du coup ça sert à rien de nous copier 10000 fois la même si c’est toujours cette erreur là :)
Cette erreur c’est forcément après l’installation quand tu navigues sur les pages, et non pas au moment de l’installation. C’est quand même bizarre de pas voir l’erreur qu’il y aurait durant l’installation…
Je suis désolé. C’est tâtonne un peu...
J’ai essayé plusieurs fois la manipulation suggérée, La difficulté venait de ce que, une fois réinstallé le plugin, le fichier mysql. log (préalablement effacé) ne réapparaissait pas dans temp/log, même en actualisant le dossier via ftp.
Du coup, j’ai effacé tous les fichiers log et j’ai recommencé la manipulation. Cette fois, mysql.log est réapparu.
Voici ce qu’il indique :
2020-05-11 13:58:33 2a01:e0a:521:4e30:78f8:f37f:c8ab:8bd (pid 10115) :Pri:ERREUR : Erreur 1091 de mysql : Can’t DROP ’page’ ; check that column/key exists
in /home/nicolasfzc/www/plugins/pages/pages_administrations.php L53 [sql_alter(),pages_vider_tables(),spip_plugin_install(),plugins_installer_dist(),do_stop(),do_action(),one_action(),action_actionner_dist(),traiter_appels_actions()]
ALTER TABLE
nicolasfzck.spip_articles DROP pageJ’espère que c’est cela.
En tout cas, un grand merci pour votre aide.
Ouais alors en gros là il dit qu’il ne peut pas désinstaller. Et ca expliquerait qu’il ne peut pas réinstaller.
Peux tu suivre cette procédure :
- désactiver le plugin
- dans la table spip_meta, supprimer l’entrée dont le nom est
pages_base_version- aller dans le dossier tmp et effacer le fichier
meta_cache.php- réactiver le plugin, il devrait dire qu’il s’installe
- nous donner les résultats des logs.
J’ai suivi la procédure mentionnée.
La première fois, je l’ai fait après avoir effacé les fichiers log. Je fichier mysql.log n’est pas réapparu dans TEMP/LOG. Mais le problème était toujours là (après avoir cliqué dans la rubrique « Pages » de l’espace privé). Le fichier mysql.log n’est réapparu qu’à partir de ce moment là. Avec le même message « Unknown column ’page’ in ’field list’ »
J’ai ressayé une seconde fois sans effacer les fichiers log, Cette fois, mysql.log était toujours là mais n’affiche que le message Unknown column ’page’ in ’field list’
Est-ce que le contenu des deux autres log (spip.log et maj.log) peut aider ?
Hum,
c’est bizarre. Tout indique que le plugin ne s’installe pas vraiment mais on a pas de message de log.
Là franchement je sèche.
Eventuellement tu peux m’envoyer des accès en privé [monprenomsanstream arobase mon prenomsanstrema point net]
Merci pour cette proposition. En fait j’ai tout désinstallé, formaté la base et j’ai recommencé. J’ai utilisé une version moins récente de spip et cela fonctionne.
Mouais, mais normalement cela devrait fonctionner AUSSI sur une version récente de SPIP. Et en régle générale c’est bien d’avoir les versions récentes, notamment pour des raisons de sécurités.
Peut être que la table était corrompu et que le formatage a permis cela.
Bref, je conseillerai de mettre à jour SPIP (après sauvegarde de la base)
Répondre à ce message
Bonjour,
J’ai installé la version 1.4.0 du plugin pages uniques.
J’ai essayé de faire fonctionner une boucle ARTICLES avec les critères page=xxxx et doublons
Exemple :
<BOUCLE_article(ARTICLES){page=test}{doublons ici}></BOUCLE_article>Mais l’id_article de la page test n’est pas ajouté à la liste des doublons !
Du coup, plus loin, l’anti-doublons ne me renvoie pas la page d’identifiant test :(
J’ai testé chez moi. Je ne pense pas que le problème vient de lien. Il vient du fait que si on ne précise ni page, ni article, ni rubrique, alors par défaut la boucle articles exclut les pages unique. Le critère tout permet de forcer cela.
Répondre à ce message
Perso, pour créer des pages particulières avec leur propre design, j’utilise une solution toute simple. Avec champs Extras, pour l’objet « Article », je crée un champs texte « ARTICLE_IDENTIFIANT_PAR_NOM ».
Je renseigne ce champ dans chaque article avec un nom (exemple « simple »).
Je crée une page que je nomme « simple » dans mon dossier Inclure.
Et dans la page Article, je mets la boucle ci-dessous, à l’endroit qui va accueillir les infos de chaque template.
Et voilà ! Je peux créer autant de templates différents.
Il est également possible de procéder ainsi pour les rubriques.
J’ajoute à cela que je n’ai plus besoin des plugins « composition », ni « pages-uniques ».
On peut faire varier l’idée en remplaçant le champs texte par des boutons radio. Ainsi, n’importe quel rédacteur peut choisir pour chaque article (ou rubrique) le template qui va bien...
Perso, ça me donne de sacrées possibilités de présentations...
Pour une rubrique, je met cette boucle :
Là, dans Champs Extras, ma ligne de texte s’appelle « presentation »...
Libre à toi de réinventer en moins complet et en moins générique des plugins qui existent déjà et qui sont maintenus en commun par la communauté donc pérennes. :D
ben, ce n’est pas un plugin... simplement une boucle, c’est tout ! C’est justement pour éviter d’installer pleins de plugins...
Répondre à ce message
Bonjour,
Je dispose de SPIP 3.2.4 avec le plugin Pages v1.4.0. En suivant la documentation, je crée une page avec le champ
page=testpuis je crée un squelette test.html. Lorsque je veux voir la page en ligne, c’est le squelette article.html qui est appelé et non test.html. La fonctionnalité ne marche pas/plus ?Après discussion sur IRC, il s’avère que cette fonctionnalité n’a jamais été implémentée et qu’il est nécessaire d’avoir le plugin Compositions pour ce besoin. C’est fort dommage ça aurait été très pratique
La doc a été mise à jour pour plus de clarté du coup
Répondre à ce message
Bonjour,
En squellette sommaire.html, j’ai une boucle qui liste les articles d’un mot-clé « carreau »,
mais je ne comprend pas pourquoi il ne liste pas les pages uniques portant ce même mot-clé « carreau ».
voici ma boucle :
Une idée ?
Merci d’avance.
parce que le principe des pages uniques est d’etre exclus des boucles articles, sauf si on demande explicitement un id_article précis ou une page précise.
Actuellement je ne vois pas de solution « propre » pour obtenir ton comportement. Il y a bien
{id_article?}mais c’est risqué, car si tu a unid_articlepassé en environnement, ca pète.Donc il faudrait améliorer le plugin. Rastapopoulos, que pense tu d’un critère
{page_peu_importe}?Euh, il suffit juste d’utiliser le critère
{tout}.a oui, j’ai loupé cela en relisant le code. donc j’ai rien dit ;-) donc Fennec72 tu a ta réponse.
c’était bien cela :
Merci
En fait, il faut aussi tenir compte du statut des articles, et du cas des articles sous embargo (dans le futur).
Donc :
J’ai trouvé beaucoup plus simple comme code :
Répondre à ce message
Bonjour,
J’ai effectué ce matin la MAJ vers Pages 1.3.8. et là surprise mon site ne s’affichait plus, plus d’accès à l’interface privée non plus. J’ai donc par ftp remis la version Pages 1.3.7. et miracle tout est revenu.
Je ne sais pas où se situe le problème. Je suis sous SPIP 3.2.1. Escal 4.2.33.
Merci de votre aide.
Yann
Il faudrait activer l’affichage des erreurs.
Quand je regarde mon fichier error_log je trouve ceci sur plusieurs lignes à l’heure où j’ai installé la MAJ :
[Thu Jan 17 09:18:29 2019] [warn] [client 90.107.58.69] mod_fcgid : stderr : PHP Fatal error : Cannot redeclare autoriser_rubrique_creerarticledans() (previously declared in /var/www/vhosts/maisondesprovinces.fr/httpdocs/plugins/auto/autorite/v0.10.20/inc/autoriser.php:254) in /var/www/vhosts/maisondesprovinces.fr/httpdocs/plugins/auto/pages/v1.3.8/pages_autorisations.php on line 197
Bonjour,
https://zone.spip.net/trac/spip-zone/changeset/113485/spip-zone devrait résoudre ton problème.
Merci du signalement.
Merci beaucoup ! :-)
Yann
Euh, en mettant à jour j’ai cette erreur : Impossible de lire certaines descriptions XML
Erreur dans les plugins : auto/pages/v1.3.9
Pour le XML, ya que le numéro qui a changé dedans, donc je ne vois pas pourquoi ça péterait plus que le précédent. Super bizarre
https://zone.spip.net/trac/spip-zone/changeset/113485/spip-zone
Je vois qu’il n’y a que 2 fichiers modifiés. Je peux essayer juste de remplace le fichier pages_autorisations.php sans toucher le fichier xml.
Yann
Bonjour,
Je viens d’avoir la même expérience, sur un SPIP 3.2.1 avec la version 1.3.8 du plugin Pages : même message d’erreur (Impossible de lire certaines descriptions XML). ça ne semble donc pas venir de la correction d’aujourd’hui.
Alors en remplaçant juste l’ancien fichier pages_autorisations.php par le nouveau et sans remplacer le fichier XML ça fonctionne. dès qu’on met le nouveau fichier XML ça foire. J’ai donc essayé en modifiant dans l’ancien fichier XML le numéro de version pour indiquer 1.3.9 ainsi que le https pour le lien SPIP en ligne 8 et ça marche. Plus d’erreur et la version du plugin indique bien 1.3.9
Je ne vois pas ce qu’il peut y avoir sur le fichier XML livré avec la MAJ qui pose problème !
Yann
Bonjour, La version 10 corrige le problème pour activé le plugin
Merci !
Yann
Merci beaucoup, l’installation se fait désormais sans problème.
Répondre à ce message
Alors je suis désolé de jouer les rabat-joie plusieurs années après mais j’ai trouvé une faille :)
En fait les pages uniques ne sont belles et bien pas indexées automatiquement, et si le .htaccess n’autorise pas la découverte la page est cachée, ça c’est nickel ! Par contre les commentaires bas de page (comme celui-ci) s’il y en a, sortent sous « Messages » dans les résultats d’une recherche.
C’est lorsque j’ai changé un article en page à la suite de son obsolescence partielle que j’ai constaté cela. Perso je ne suis pas vraiment gêné car je ne la dissimule pas complètement, juste je la cache un peu (et puis elle reste indexée dans les moteurs de recherches), mais j’estime qu’une page qui serait crée dans un but privée ne pourrait pas être commentée sous peine de pouvoir être trouvée et j’estime cela un peu dommage
Hello,
je ne vois pas trop ce que tu veux dire car ce plugin n’a jamais eu pour but de CACHER des articles. Au contraire ce sont des articles normaux, avec les mêmes statuts, donc publié, etc. Seulement ils ne sont RANGÉS dans aucun rubrique. C’est juste un truc de rangement.
Si tu veux dépublier ou archiver des trucs, ya un plugin Archives pour ça à priori.
Bah comme l’énoncé’ du plugin dit « articles qui ne sont rattachés à aucun rubriquage particulier » on peut je pense présumer que si aucun linkage n’est créé la « page unique » n’est pas découvrable par le commun des mortel ? En tous cas c’est bien le cas, même par les robots d’indexations, et même lorsqu’on lance une recherche sur la page avec le moteur de recherche de SPIP, la page ne sort pas. Moi je dis assez parfait, et c’est d’ailleurs cela qui m’avait fait conserver ce plugin : des pages un peu cachées jusqu’à un éventuel linkage, exactement ce que je cherchais.
Mais parfait jusqu’à ce qu’un visiteur publie un commentaire sur la page. Car ce commentaire devient, lui, trouvable via le moteur de recherche dans SPIP. Et ceci rend alors la page découvrable !
C’est vraiment le seul truc accessible que j’ai pu apercevoir qui rende la page découvrable, je trouve cela vraiment dommage
En capture une recherche de la page unique « Indian Road » sur le site https://docsanscible.fr et qui comporte un commentaire. Comme on peut le constater la page n’est pas trouvée, par contre le commentaire l’est.
Je ne sais pas quel genre de boulot ça peut être, perso de remédier à ça, je ne crois pas avoir les connaissances pour le faire, mais franchement je pense que ça mériterait
Bé non, il n’y a rien à faire, ce plugin n’a pas et n’aura jamais pour but de cacher quoi que ce soit. Ce sont des articles publiés, donc accessibles à tout le monde. Après ça dépend des squelettes du site, et ça ça peut être 12000 trucs différents suivants les sites, chacun fait ce qu’il veut. Si tu veux cacher des choses, soit tu modifies tes squelettes, soit tu utilises un plugin qui dépublie ou met en archive réellement les articles.
Non merci je ne désire pas archiver ni dépublier.
J’utilise le dist
Je considère que les « articles qui ne sont rattachés à aucun rubriquage particulier » du plugin « Pages uniques » recèlent en réalité une façon de se faire rattacher. Je pense que ça doit pouvoir se résoudre mais je n’en ai pas les moyens.
Ce sera tout merci
Je n’ai pas compris la phrase "« Pages uniques » recèlent en réalité une façon de se faire rattacher"
En gros, si j’ai bien compris, vous ne voulez pas afficher les résultats des forusm dans le formulaire de recherche ?
Par ce que vraiment, page unique ce n’est pas fait pour cacher une page !
« vous ne voulez pas afficher les résultats des forums dans le formulaire de recherche »
C’est exactement cela :) Ne pas afficher les résultats des forums (j’aurais sans doute du employer le bon mot d’entré, désolé) des pages uniques dans le moteur de recherche de SPIP :)
Parce qu’il est chouette ce plugin je veux dire ! C’est même pas merci c’est pire :) On crée une page unique, on peut travailler un peu à plusieurs auteurs dessus, la mettre en ligne et la montrer via juste son adresse sans code d’accès, recevoir des avis aussi en commentaires dans le forum, continuer à travailler tout en la laissant publiée, et tout ça sans que les visiteurs de passage ne soient en mesure de la trouver :) Pas complètement cachée (on ferait autrement) : juste un peu. Juste assez :)
Et ça ce plugin le procure par défaut ! Tant qu’il n’y a pas un commentaire :)
Je vous remercie en tous cas de l’attention que vous m’avez porté :)
Oui, c’est vraiment pas l’usage pour lequel ca a été prévu, même si avec la dist ca peut correspondre.
Donc il vous faut masquer les forums des resultats de recherches. Vous êtes avec la dist :
- créer (si ce n’est pas deja fait) un dossier squelettes (à coté de ecrire, squelettes-dist, etc).
- copier squelettes-dist/recherche.html dans ce dossier squelettes
- modifier squelettes/recherche.html en supprimant :
Ah ou enlever les commentaires des résultats de recherches oui :)
Comme ça maintenant je sais où ça se tient ? :) Je vais regarder si y’a moyen de s’arranger avec la boucle pour le fun :)
En tous cas merci pour votre présence et le coup de main :)
Il veut pas virer les forums, il veut virer juste les forums qui sont sur des pages uniques.
Répondre à ce message
Bonjour,
Lorsque :
- l’on crée un article virtuel sur une page
- Que les URLs du site sont arborescentes
L’article virtuel est redirigé sur une page 404.
Dès que la page est transformée en article, la redirection fonctionne.
Quelqu’un a t-il une solution pour pallier à ce problème ?
Bonjour Yohooo,
Je viens de vérifier, en 3.2-dev et en 3.1, et je ne reproduis pas entièrement ce comportement.
En fait ça fonctionne dans les 2 cas par défaut.
Sauf. Sauf si un autre jeu d’URLs était utilisé auparavant (ou après), par exemple ’Libre’. Dans ce cas, pour les URLs pages, une nouvelle URL est généré qui ne contient pas le champ ’id_parent’. Et le mélange de ces 2 monde semble les perturber. C’est peut être un problème dans ce plugin…
Toujours est-il que la correction est assez simple cependant : supprimer l’URL qui n’a pas le id_parent (-1) renseigné, lorsque tu passes en URLs Arborescente (la recréer au besoin ensuite), pour les articles pages.
Précisions : en 3.2-dev je ne reproduis pas de 404 même si le parent n’est pas renseigné.
Visiblement il y a eu amélioration entre temps.
Hello Mathieu,
Merci pour la solution.
Sur ma version, en 3.1, supprimer les URL n’ayant pas d’id_parent (-1) ne suffit pas. Il faut tout simplement en ajouter une nouvelle.
Répondre à ce message
Ajouter un commentaire
Avant de faire part d’un problème sur un plugin X, merci de lire ce qui suit :
Merci d’avance pour les personnes qui vous aideront !
Par ailleurs, n’oubliez pas que les contributeurs et contributrices ont une vie en dehors de SPIP.
Suivre les commentaires : |
|
