Retours sur l’usage de Xray et CacheLab
Version 27 — Janvier 2019 — JLuc
Certains détails de cet article ne sont plus à jour.
Voir
- Doc : XRay, un explorateur des caches SPIP
- Doc : API CacheLab 1. Action sur des caches ciblés
- Compléments CacheLab et todo
- Complément et todo XRay
Découvertes
- BUG : Contamination des caches non sessionnés : Si dans un squelette ya une suite d’INCLURE dynamiques non sessionnés avec au milieu d’eux un inclure sessionné, plusieurs inclusions tous ceux aprés l’inclure sessionné seront aussi, indûement, sessionnés. Un fix existe mais n’a pas encore intégré été à spip ( cf (cf trac , carnet ). ) D’autres types de circonstances provoquent la création de caches sessionnées alors qu’ils ne devraient pas l’être, et l’explosion du cache, nuisant aux performances du site.
- Dé-Dynamisation des inclusions dynamiques : L’inclusion d’un squelette statique dé-dynamise tous les caches des inclusions dynamiques faites par ce squelette. À mieux tester
Exemple : SiA #INCLUE B qui <INCLUE> C, alors C est en fait inclu statiquement dans B et donc dans A. Une conséquence est que si C est sessionné, alors B et A le sont aussi.
DEV : On pourrait concevoir une nouvelle forme d’inclusion dynamique qui ne serait PAS dé-dynamisée lors d’une éventuelle inclusion statique.
- Attention avec les compositions : les squelettes des compositions sont appelés par l’inclusion d’un autre squelette avec un argument composition en plus. Le cache résultant a le nom du squelette principal, mais la valeur du squelette associé (champ ’source’ du cache) est le squelette de la composition.
- Les caches sessionnés ont un « talon » = stub, cache creux, sans suffixe _ ni contenu html, qui ne comprend comme métadonnées que l’invalideur
session=''etlastmodified. Les talons ne sont pas des caches de squelette, mais des marqueur de sessionnage : ils servent uniquement à indiquer que les caches de ce squelette sont sessionnés (cf source : creer_cache et public_cacher). Et alors, c’est un autre cache qui contient le contenu et les métadonnées du squelette : celui avec le suffixe d’identifiant de session.Il y a autant de talons qu’il y a de couples (squelette, contexte). Pour chacun de ces talons, il y a autant de caches qu’il y a de sessions.
Xray propose
- des boutons pour, à partir d’un cache sessionné, accéder à la liste de tous les caches ayant le même talon.
- un filtrage des talons. Combiné avec le filtrage par « cache sessionnés » ou « non sessionnés », et avec l’option « Lister les squelettes », c’est un moyen rapide d’accéder par exemple à la liste des squelettes sessionnés.
- Quand un modèle sessionné est inséré dans l’éditorial d’un objet, c’est le squelette affichant ce dernier qui est sessionné. L’inclusion du modèle est statique, pareil qu’avec #INCLURE. Le modèle n’a pas de cache du tout. Normalement, on peut avec SPIP3 spécifier une durée de cache pour le modele, mais avec SPIP 3.1.8 je ne vois aucun effet sur la durée du cache du squelette incluant donc je me demande si ça marche ou comment ça se passe.
- Les squelettes appelés comme en tant que
paged’une url ont en général un nom de cache qui se termine par/, tandis que le même squelette, appelé par un INCLURE, n’a pas ce/à la fin, même s’il a le même environnement. Y a t il une bonne raison à cela ?
Mais certaines pages accédées en tant que page d’une url ont un nom de cache suffixé par /spip ou par /1234 où 1234 est le N° de l’objet éditorial. :
-...8b79-gis_json/spippour le cache degis_json.html
-...928-compte/spip
-...f921a-saisies.css/spip
-...fe22-mestrucs/spip
-...a40f-backend/spip
-...a12b-untruc/1234
Statistiques / caches (archives)
Expérimentation
Lors des tests les temps de filtrage avec cachelab sont de l’ordre de .1 à .5 secondes lorsqu’il y a 10000 à 20000 caches en mémoire. C’est supportable lorsque le filtrage et l’invalidation n’ont lieu qu’à la demande lorsqu’on crée ou modifie un contenu, mais il serait intéressant tout de même de limiter cet impact.
Ces chiffres sont donnés « sans garbage collector ». Or, sans garbage collector, 90% des caches sont périmés en général si on ne fait rien à ce sujet (xray donne ces stats). Par défaut, Cachelab s’occupe de ce garbage collector, au fur et à mesure qu’il découvre des caches invalides. Ainsi, il n’y a quasiment que des caches valides dans APCCache. On divise donc par 10 (en moyenne) les temps de recherche pour invalidation sélective... ou on multiplie par 10 le nombre de cache qu’il est possible de gérer à durée égale.
Limites de l’expérimentation
Si en moyenne 98% des squelettes sont en cache, alors il est peu utile de cibler précisément quels caches doivent être invalidés [1]
Le rendement du cache est d’autant plus faible que les internautes créent souvent des articles, ou déposent un commentaire... ou même ajoutent ou retirent un favori avec le plugin favoris, car par défaut avec SPIP, tous les caches sont invalidés à chacune de ces opérations.
En pratique, sur le site de dev, xray montre des taux de rendement du cache bien moindres (rapport : nombre d’accés en cache / nombre d’accés total) sur un site où il y a des créations ou modifications de contenus (saisie de nouveaux articles ou commentaires, choix de favoris, administration du site via ecrire).
À part pour les fichiers js compressés et css, qui ne sont jamais modifiés, le taux n’atteint jamais 98%. Il oscille entre % (juste après une invalidation globale) et un taux maximal d’efficacité qui sera d’autant moindre que le site est actif (20%, 60%, 70%...). Les graphiques plus loin montrent un exemple d’évolution de cette efficacité sur un site en production.
L’expérience
Sur un site
- sans garbage collector
- sans invalidation ciblée du cache avec CacheLab
J’ai relévé les origines des invalidations au cours d’une période test :
- 172 pour cause de favoris
- 224 pour causes d’objets principaux
- 232 pour gis
- 192 pour id_document
- 260 pour auteurs
- pas de relevé pour les forums car il n’y en a que dans l’admin et il n’y a pas eu d’admin
Puis j’ai mesuré :
- la durée entre 2 invalidations (en secondes)
- le ratio d’efficacité du cache au moment de l’invalidation (nb hits /nb accés)
- le rendement du cache au moment de l’invalidation (hits×taillemémoire / accés×taillemémoire)
Rq : le ratios et le rendement sont calculés hors javascript et hors css. Pour les fichiers javascript et css, les taux sont bien plus élevés.
Les graphes suivants présentent les résultats pour 3 jours comprenant weekend (du 2018-03-09 17:00 au 2018-03-12 16:34) et présentent 80 mesures.
Au cours de cette période, il y a eu sur le site
- 700 visites par jour,
- 15 créations d’objets éditoriaux principaux
- 60 créations de forum
- 1 seule suppression de favori
- aucune édition par l’admin (c’est le weekend !)
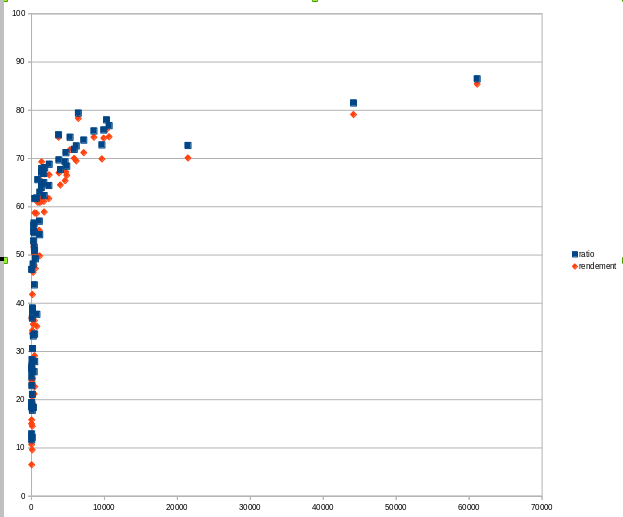
On voit
- que le rendement est toujours légèrement inférieur au ratio : les gros caches sont moins souvent réutilisés. Mais globalement, la différence n’est pas significative.
- c’est le matin, après une nuit sans création ou modification de contenu, que le cache dépasse tout juste 80%
- la moyenne des ratios est de 52 et la médiane est de 56
En excluant les « premières invalidations du matin » on peut zoomer :
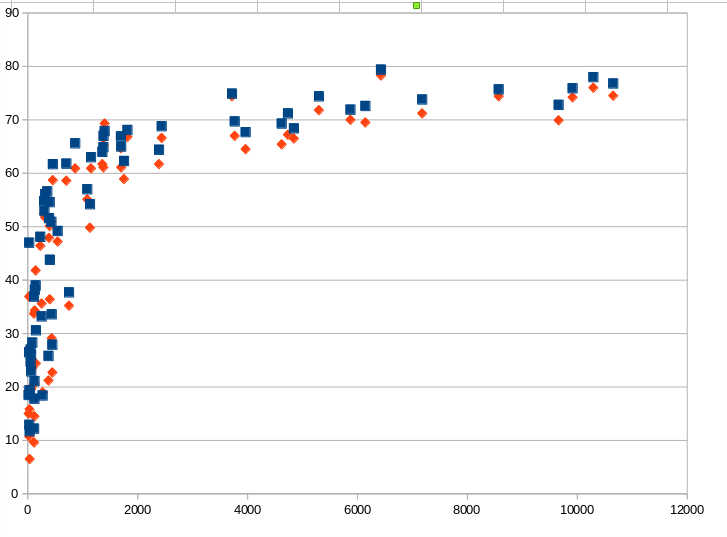
Le calcul indique que la moyenne des ratios est de 50 et la médiane est de 55. La moitié des ratios est inférieur à 55%
Sans faire de calculs précis on voit qu’il faut en moyenne 15mn sans invalidation pour atteindre 55% d’efficacité et environ 1h30 sans invalidation pour atteindre 70%, ce qui n’arrive que dans moins de 15% des cas.
Il faudra retester avec garbage collector et après application d’une stratégie d’invalidation sélective.
Toutes les versions
- 36 - 86.202.xx.xx, Février 2021
- 35 - JLuc, Janvier 2021
- 34 - JLuc, Novembre 2020
- 33 - JLuc, Novembre 2020
- 32 - JLuc, Mai 2019
- 31 - 78.242.xx.xx, Mai 2019
- 30 - 78.242.xx.xx, Mai 2019
- 29 - JLuc, Janvier 2019
- 28 - JLuc, Janvier 2019
- 27 - JLuc, Janvier 2019
- 26 - JLuc, Décembre 2018
- 25 - JLuc, Décembre 2018
- 24 - JLuc, Décembre 2018
- 23 - JLuc, Octobre 2018
- 22 - JLuc, Octobre 2018
- 21 - JLuc, Avril 2018
- 20 - JLuc, Mars 2018
- 19 - JLuc, Mars 2018
- 18 - JLuc, Mars 2018
- 17 - JLuc, Mars 2018
- 16 - JLuc, Mars 2018
- 15 - JLuc, Mars 2018
- 14 - JLuc, Mars 2018
- 13 - JLuc, Mars 2018
- 12 - JLuc, Mars 2018
- 11 - JLuc, Mars 2018
- 10 - 78.242.xx.xx, Mars 2018
- 9 - 78.242.xx.xx, Mars 2018
- 8 - JLuc, Mars 2018
- 7 - JLuc, Mars 2018
- 6 - JLuc, Mars 2018
- 5 - JLuc, Mars 2018
- 4 - JLuc, Mars 2018
- 3 - JLuc, Mars 2018
- 2 - JLuc, Mars 2018
- 1 - JLuc, Version initiale